
توی فصل اول کتاب System Design Interview نوشتهی Alex Xu، نویسنده درباره این صحبت میکنه که چطور میتونیم یه سیستم رو از صفر تا مقیاس یک میلیون کاربر گسترش بدیم. توی همین فصل، یه سری تکنیک کاربردی معرفی میکنه که در فصلهای بعدی کتاب هم مدام بهشون برمیگرده و ازشون استفاده میکنه.
توی این مقاله، میخوام تمام اون تکنیکهایی که توی فصل اول گفته رو به زبان ساده توضیح بدم. اینطوری وقتی میخوایم سراغ طراحی سیستمهای واقعی بریم، یه جعبهابزار ذهنی آماده داریم که خیلی کمکمون میکنه.
از نظر من، این تکنیکها مثل مواد اولیه آشپزیان. مثلاً برنج، گوشت، پیاز، گوجه و… وقتی این مواد اولیه رو شناختیم، توی ادامهی مسیر یاد میگیریم چطور باهاشون غذاهای مختلف درست کنیم — یا بهتر بگم، چطور سیستمهای مختلف طراحی کنیم.
setup کردن یک single server
برای شروع طراحی یک سیستم، لازم نیست از همون اول کار سراغ معماریهای پیچیده و سرورهای زیاد بریم. بهترین کار اینه که خیلی ساده شروع کنیم و کمکم با توجه به نیازهایی که به وجود میان، طراحیمون رو بهبود بدیم.
در واقع، شروع با یک سرور واحد کاملاً منطقیه. همین سرور میتونه تمام بخشهای سیستم — از دیتابیس گرفته تا بکاند و فرانتاند — رو اجرا کنه. وقتی که سیستم رشد میکنه و ترافیک بالا میره، اونوقته که سراغ تکنیکهای مقیاسپذیری میریم.
حالا به دیاگرام پایین دقت کنید، تا قدمبهقدم براتون توضیح بدم که این ساختار ساده چطوری کار میکنه و چه چیزهایی توش لحاظ شده.
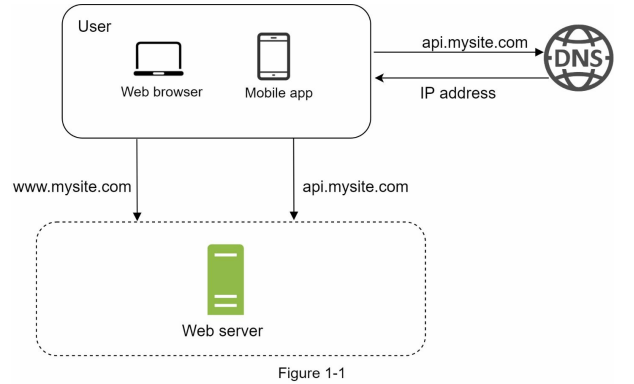
برای اینکه بهتر متوجه بشیم توی دیاگرام بالا چه اتفاقی میافته، اول باید بفهمیم که جریان درخواست (Request Flow) چطور پیش میره. یعنی وقتی یه کاربر یه درخواست به سیستم میفرسته، دقیقاً چه مراحلی طی میشه تا به پاسخ برسه.
درک درست از request flow کمک میکنه بهتر بفهمیم که هر بخش از سیستم دقیقاً چه نقشی داره و در آینده، اگر بخوایم سیستم رو گسترش بدیم یا بهینه کنیم، دقیقاً باید از کجا شروع کنیم.
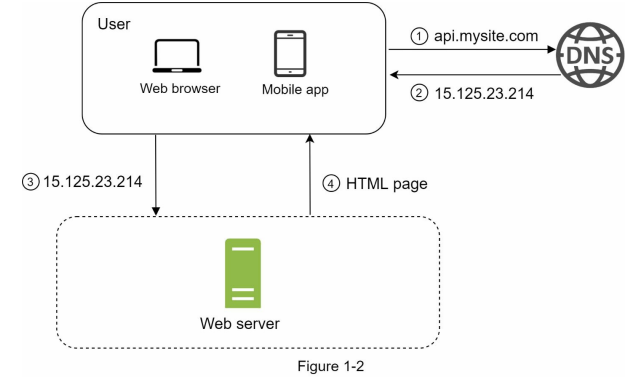
- ابتدا کاربر به آدرس
api.mysite.comریکوئست میزند. این آدرس توسط DNS که مخفف Domain Name System است resolve میشود؛ یعنی دامنه به یک آدرس IP تبدیل میشود. این فرآیند شبیه دفترچه تلفن است که هر نام به یک شماره اختصاص دارد. - بعد از resolve شدن، آدرس IP مرتبط با سرور (مثلاً
15.125.23.214) به مرورگر یا کلاینت برگشت داده میشود. - پس از دریافت IP، مرورگر یا کلاینت یک درخواست HTTP به سرور میفرستد.
- سرور درخواست را پردازش میکند و در پاسخ، بسته به نوع درخواست، خروجیای مانند HTML یا JSON برمیگرداند.
همونطور که توی دیاگرام بالا مشخص هستش، ترافیک هایی که به سمت web server ما میان از web application و mobile application ها هستن.
- Web Applicationها از زبانهای مختلفی مثل Go، Java، Python و… استفاده میکنن تا بخشهایی مثل منطق بیزینس (Business Logic)، ذخیرهسازی دیتا (Storage) و سایر عملیات بکاند رو پیادهسازی کنن. از طرف دیگه، برای نمایش سمت کاربر از HTML و JavaScript برای بخش Presentation استفاده میشه.
- Mobile Applicationها معمولاً با استفاده از پروتکل HTTP با سرور ارتباط برقرار میکنن. در پاسخ APIها هم اغلب از فرمت JSON برای انتقال دیتا استفاده میشه، چون ساده و خواناست. یه مثال ساده از JSON رو این زیر میتونید ببینید:
{
"status": true,
"message": "Product successfully added to cart.",
"data": {
"cart_summary": {
"total_items": 3,
"total_price": 1250000,
"discount": 250000,
"final_price": 1000000,
"free_shipping": true
},
"product_added": {
"id": 42,
"name": "Wireless Headphones",
"price": 500000,
"quantity": 1
}
}
}
دیتابیس
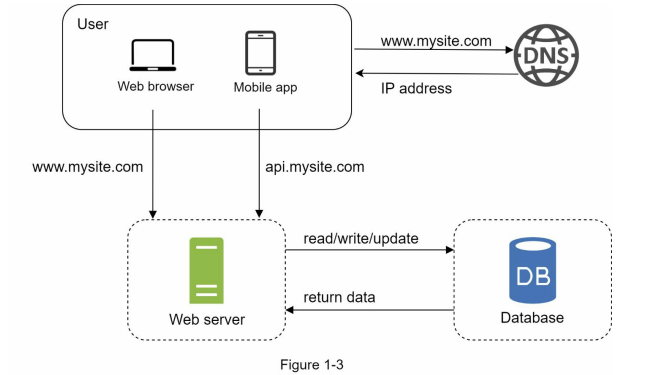
حالا فرض کنیم تعداد کاربرهای ما زیاد شده. با افزایش کاربران، طبیعتاً تعداد ریکوئستها هم بالا میره. اینجاست که وقتشه یه قدم جدیتر برای مقیاسپذیری برداریم:
جدا کردن دیتابیس از سرور اصلی.
یعنی چی؟ یعنی بهجای اینکه همهچی (وباپلیکیشن، API و دیتابیس) روی یه سرور باشن، دیتابیس رو روی یه سرور مجزا قرار میدیم. این کار باعث میشه که:
- ترافیک مربوط به وب یا موبایل (Web Tier) از ترافیک پایگاهداده (Data Tier) جدا بشه.
- بتونیم هر کدوم رو بهصورت مستقل scale کنیم، یعنی مثلاً فقط دیتابیس رو قویتر کنیم یا فقط وبسرور رو افزایش بدیم، نه کل سیستم رو یکجا.
این یکی از اولین قدمهای مهم توی مسیر ساخت یه سیستم مقیاسپذیره.
از چه دیتابیسی استفاده بکنیم؟
ما معمولاً با دو نوع دیتابیس سر و کار داریم: دیتابیسهای رابطهای (relational) و دیتابیسهای غیررابطهای (non-relational). توی کتاب معروفی به اسم Designing Data-Intensive Applications به صورت خیلی عمیق به این موضوع پرداخته شده، ولی اینجا میخوایم خیلی ساده و خلاصه، همونطور که توی کتاب System Design Interview مطرح شده، بهش نگاه کنیم.
دیتابیسهای رابطهای که بهشون RDBMS هم گفته میشه (مخفف relational database management system)، دادهها رو توی جداول (Tables) و سطرها (Rows) ذخیره میکنن و امکان انجام عملیاتهایی مثل Join روی این جدولها رو فراهم میکنن. دیتابیسهایی مثل PostgreSQL، MySQL، Oracle و SQL Server از معروفترینهای این دسته هستن و سالهاست که بهعنوان انتخاب اصلی در خیلی از پروژهها استفاده میشن.
از طرف دیگه، دیتابیسهای غیررابطهای یا همون NoSQL وجودplugins.php دارن که برای شرایط خاصی طراحی شدن. این نوع دیتابیسها مثل CouchDB، Neo4j، Cassandra، HBase و Amazon DynamoDB، دادهها رو به شکلهای مختلفی ذخیره میکنن و برخلاف RDBMS، عملیاتهایی مثل Join رو معمولاً پشتیبانی نمیکنن. دیتابیسهای NoSQL بهطور کلی به چهار دستهی key-value store، document store، column store و graph store تقسیم میشن.
در بیشتر موارد، دیتابیسهای رابطهای میتونن نیازهای ما رو بهخوبی برطرف کنن. این نوع سیستمها سالهاست که استفاده میشن و پایداری و کاراییشون رو نشون دادن. اما بعضی وقتها شرایطی پیش میاد که دیتابیسهای رابطهای گزینه مناسبی نیستن و بهتره سراغ NoSQL بریم. مثلاً:
- اپلیکیشن ما به latency بسیار پایین نیاز داره
- دیتای ما ساختاری نداره و یا همچنین دیتا ما به شکل رابطه ای نیست
- فقط نیاز داریم که دیتا رو serialize و deserialize بکنیم
- نیاز داریم حجم زیادی از دیتا رو دخیره بکنیم
Vertical scaling در مقابل Horizontal scaling
Vertical scaling که بهش scale-up هم میگن و توی فارسی بهش مقیاسپذیری عمودی گفته میشه، یعنی اینکه ما به یه سرور موجود، منابع بیشتری مثل CPU، RAM و غیره اضافه کنیم. در مقابلش، Horizontal scaling قرار داره که بهش scale-out هم میگن و به معنی اضافه کردن تعداد سرورها برای تقسیم بار سیستمه. این روش به ما این امکان رو میده که چند سرور داشته باشیم و بتونیم بار رو بینشون پخش کنیم.
وقتی سیستم ما هنوز ترافیک زیادی نداره، Vertical scaling یه گزینه سریع و سادهست چون فقط با ارتقا دادن یه سرور میتونیم عملکرد سیستم رو بهتر کنیم. اما این روش چندتا ایراد مهم داره:
- Vertical scaling محدودیت سختافزاری داره، یعنی نمیتونیم بینهایت CPU و RAM به یه سرور اضافه کنیم. یه جایی به سقف میخوریم.
- Vertical scaling دو اصل مهم یعنی redundancy و failover رو نداره. یعنی اگه اون یه دونه سرور از دسترس خارج بشه، کل سیستم میخوابه و سایت یا اپلیکیشن ما down میشه.
در عوض، Horizontal scaling برای سیستمهای بزرگتر مناسبتره، چون محدودیتهای scale-up رو نداره و میتونه با اضافه کردن سرورهای بیشتر، فشار رو بهتر پخش کنه و پایدارتر باشه.
حالا فرض کنید که تعداد ریکوئستهای ما زیاد شده و دیگه یه سرور جواب نمیده. خیلی از ریکوئستها یا fail میشن یا با تأخیر زیادی پاسخ داده میشن. اینجاست که باید به فکر اضافه کردن سرورهای بیشتر باشیم. اما یه سوال مهم پیش میاد: چطور ریکوئستها رو بین این سرورها تقسیم کنیم؟ اینجاست که پای یه مفهوم خیلی مهم به اسم Load Balancer وسط میاد.
Load balancer
Load balancer ریکوئستهایی که از سمت کاربرها به سیستم ما میان رو بین سرورهایی که داریم به صورت مساوی یا هوشمندانه تقسیم میکنه. این کار باعث میشه که فشار روی یه سرور خاص نیفته و همه سرورها به شکل متعادل مشغول پردازش بشن.
در سادهترین حالت، load balancer میتونه هر ریکوئست جدید رو به یکی از سرورها به صورت نوبتی (Round Robin) بفرسته. اما توی شرایط پیچیدهتر، ممکنه از الگوریتمهایی استفاده کنه که بر اساس تعداد اتصالهای فعال یا بار فعلی هر سرور تصمیمگیری میکنن. نتیجهاش اینه که سیستم ما میتونه ترافیک بالا رو مدیریت کنه و کاربرها تجربهی سریعتری داشته باشن، بدون اینکه متوجه بشن درخواستشون روی کدوم سرور اجرا شده.
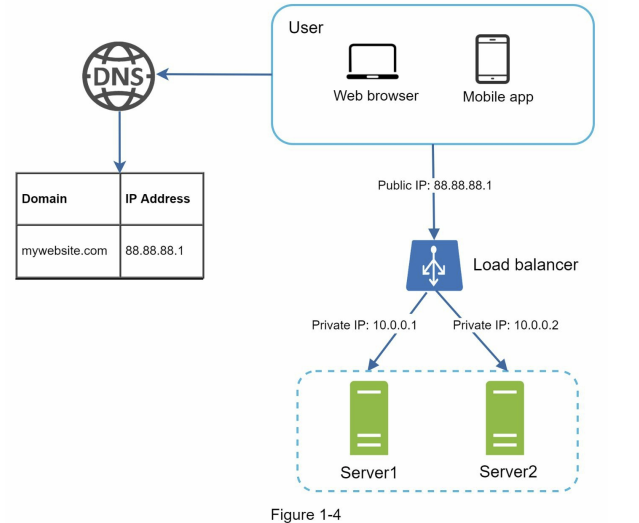
همونطور که توی تصویر بالا میبینید، کلاینتهای ما از طریق یه Public IP به load balancer وصل میشن. از اون طرف، وبسرورهای ما دیگه Private IP دارن، یعنی کلاینتها بهصورت مستقیم بهشون دسترسی ندارن. این کار چندتا مزیت داره: اول اینکه امنیت بیشتر میشه، چون فقط سرورهایی که داخل یه شبکهی مشخص هستن میتونن همدیگه رو ببینن و این سرورها از سطح اینترنت عمومی قابل دسترسی نیستن. ارتباط load balancer با وبسرورها از طریق همین private IPها برقرار میشه.
با اضافه کردن load balancer و یک سرور جدید، تونستیم مسئلهی عدم تحمل خطا (no failure) رو برطرف کنیم و availability (در دسترس بودن) سیستم رو بالا ببریم.
- اگه Server 1 از دسترس خارج بشه، load balancer تمام ترافیک رو به سمت Server 2 هدایت میکنه، و این باعث میشه که سایت ما بهطور کامل از دسترس خارج نشه و کاربرها همچنان بتونن از سرویس استفاده کنن.
- اگه تعداد ریکوئستهای ما خیلی زیاد بشه و دو تا وبسرور جوابگو نباشن، خیلی راحت میتونیم یه وبسرور جدید به سیستم اضافه کنیم و load balancer ریکوئستها رو بین سه سرور به صورت مساوی یا هوشمند پخش میکنه.
ولی هنوز یه مشکل باقی مونده: دیتابیس ما همچنان یه نقطهی بحرانیه. یعنی اگه از دسترس خارج بشه، کل سیستم به مشکل میخوره. برای حل این مشکل، یه تکنیک رایج وجود داره به اسم Database Replication که کمک میکنه availability دیتابیس رو هم بالا ببریم.
Database replication
توی فرآیند replication، ابتدا باید یه رابطهی master/slave بین دیتابیسها تعریف کنیم. یعنی یه دیتابیس داریم به اسم master که همهی عملیاتهایی مثل Create، Update و Delete روی اون انجام میشن. بعد از اون، چند دیتابیس دیگه داریم که از master کپی شدن و بهشون slave میگیم. این دیتابیسهای slave فقط برای عملیات read استفاده میشن.
در اکثر سیستمها، تعداد readهایی که به دیتابیس زده میشن خیلی بیشتر از writeها هست. یعنی کاربرها بیشتر دارن دادهها رو میخونن تا اینکه بخوان چیزی توی سیستم بنویسن یا آپدیت کنن. به همین خاطر، برای بالا بردن سرعت و تحمل بار بیشتر، میتونیم تعداد دیتابیسهای slave رو بیشتر کنیم. اینطوری درخواستهای خواندن بین چند دیتابیس پخش میشن و فشار از روی master برداشته میشه، در نتیجه هم performance بهتر میشه و هم availability دیتابیسهامون بالا میره.
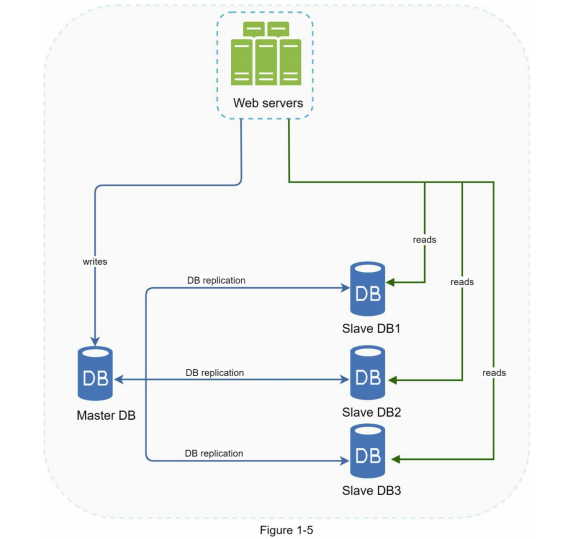
از مزایای مهمی که database replication برای ما فراهم میکنه میتونیم به موارد زیر اشاره کنیم:
- Performance بهتر: توی مدل master/slave، همهی عملیاتهای نوشتن (write) فقط روی دیتابیس master انجام میشن و همهی خواندنها (read) روی slaveها صورت میگیرن. این جداسازی باعث میشه بتونیم درخواستها رو بهصورت همزمان (parallel) بین دیتابیسها پخش کنیم و در نتیجه performance سیستم به شکل قابل توجهی بهتر بشه.
- قابل اطمینان بودن (Reliability): اگه یکی از دیتابیسها به هر دلیلی از بین بره یا از دسترس خارج بشه، نگرانیای بابت از دست دادن دادههامون نداریم، چون دادهها به شکل خودکار روی دیتابیسهای دیگه replicate شده و نسخههای دیگهای ازش وجود داره.
- در دسترس بودن بالا (High Availability): در صورتی که یکی از دیتابیسها در دسترس نباشه، سیستم همچنان میتونه از دیتابیسهای دیگه استفاده کنه و به درخواستها پاسخ بده. این ویژگی باعث میشه که سایت یا اپلیکیشن ما قطع نشه و همچنان برای کاربرها فعال بمونه.
توی بخش قبلی درباره این صحبت کردیم که load balancer چطور به ما کمک میکنه تا availability سیستم رو بالا ببریم. حالا توی این بخش یه سوال مهم دیگه مطرح میشه:
اگه یکی از دیتابیسهامون از دسترس خارج بشه، چی میشه؟ طراحیای که تا اینجا انجام دادیم، برای همین سناریوها هم راهحل داره.
- اگه فقط یک دیتابیس slave داشته باشیم و اون از دسترس خارج بشه، موقتاً همهی ترافیکهای خواندن (read) به سمت master منتقل میشن. وقتی مشکل رفع شد، یه slave جدید جایگزین قبلی میشه و دوباره درخواستهای read به سمت slave برمیگردن. حالا اگه چندین slave داشته باشیم و یکی از اونها از دسترس خارج بشه، ترافیکش به شکل خودکار بین بقیهی slaveها تقسیم میشه تا وقتی که اون دیتابیس دوباره به شبکه برگرده.
- اما اگه master از دسترس خارج بشه، بلافاصله یکی از slaveها به عنوان master جدید ترفیع پیدا میکنه و همهی عملیاتهای نوشتن (write) روی اون انجام میشه. از طرف دیگه، یه دیتابیس جدید به عنوان slave جایگزین اونی میشه که ارتقا پیدا کرده، تا همچنان بتونیم عملیات replication رو ادامه بدیم.
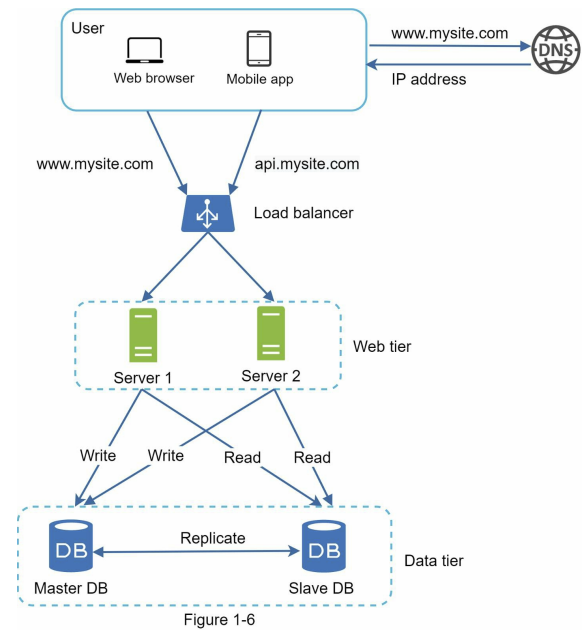
یک بار باهم دیزاین بالا رو مرور کنیم تا تصویر بهتری از کل ساختار داشته باشیم:
- کلاینت از طریق DNS آدرس مربوط به load balancer رو دریافت میکنه.
- بعد با همون آدرس به load balancer وصل میشه و درخواستش رو ارسال میکنه.
- load balancer هم درخواست HTTP رو به یکی از سرورها (مثلاً سرور ۱ یا سرور ۲) منتقل میکنه.
- وبسرورها برای پاسخ دادن به درخواست کلاینت، دیتای مورد نیاز رو از دیتابیس slave میخونن.
- در کنار این عملیات، هر درخواستی که نیاز به نوشتن دیتا داشته باشه — مثل Create، Update، Delete — از طرف وبسرورها به دیتابیس master ارسال میشه تا اونجا پردازش بشه.
حالا که یه درک خوب از دو لایهی مهم سیستم یعنی web tier و data tier پیدا کردیم، وقتشه بریم سراغ یه موضوع دیگه: بهینهسازی زمان پاسخگویی (response time).
برای این کار، میتونیم از cache برای نگهداشتن دادههای پرکاربرد و از CDN برای سرویسدهی سریعتر به فایلهای static مثل عکس، ویدیو، CSS و JS استفاده کنیم.
Cache
از cache استفاده میکنیم تا بتونیم responseهایی که اصطلاحاً سنگین هستن یا دیتاهایی که خیلی پرتکرار استفاده میشن رو بهصورت موقت توی RAM نگه داریم. این کار باعث میشه که وقتی یه ریکوئست مشابه دوباره دریافت شد، دیگه لازم نباشه از دیتابیس یا سرویسهای دیگه بخوایم دوباره اون دیتا رو بیاریم. در عوض، خیلی سریع از cache پاسخ میدیم و این باعث میشه سرعت پاسخگویی (response time) بهشدت بهتر بشه و همزمان فشار از روی دیتابیس هم برداشته بشه.
لایه کش (cache tier)
لایه کش، یه لایهی جداگانه برای ذخیرهسازی موقت دادههاست که کمک میکنه تعداد کوئریهای read به دیتابیس کمتر بشه و در نتیجه فشار زیادی از روی دیتابیس برداشته بشه. این لایه معمولاً روی RAM اجرا میشه و سرعت خیلی بالایی داره. با داشتن یک لایه کش جدا، ما این قابلیت رو داریم که بهصورت مستقل اون رو scale کنیم، یعنی اگر حجم درخواستها به cache زیاد بشه، بدون نیاز به تغییر در دیتابیس یا وبسرورها، میتونیم فقط کش رو گسترش بدیم و کارایی کلی سیستم رو بهبود بدیم.

بعد از اینکه یک request به وبسرور میرسه، سرور اول بررسی میکنه که آیا دیتای موردنظر داخل cache وجود داره یا نه. اگه دیتا داخل cache موجود باشه، همون رو خیلی سریع از cache میگیره و به عنوان response به کاربر برمیگردونه. اما اگه دیتا توی cache نباشه، سرور میره سراغ دیتابیس، اطلاعات رو از اونجا میگیره، بعد از دریافت، اون دیتا رو داخل cache ذخیره میکنه تا برای درخواستهای بعدی آماده باشه، و در نهایت response رو به کاربر برمیگردونه.
به این روش کش کردن دیتا، read-through caching گفته میشه. استراتژیهای دیگهای هم برای کار با cache وجود دارن، مثل write-through یا write-behind، که توی یه مقالهی جدا میتونیم بهشون مفصل بپردازیم.
کد زیر یک نمونه کد برای Memcached برای کش کردن دیتا هستش:

وقتی داریم از کش استفاده میکنیم، باید حتماً به چند نکتهی مهم توجه داشته باشیم تا عملکرد سیستممون هم بهینه بمونه و هم دچار مشکل ناسازگاری نشه:
- تشخیص زمان درست استفاده از کش: ما زمانی باید از کش استفاده کنیم که دیتای مورد نظر خیلی زیاد read میشه ولی کمتر تغییر میکنه. چون cache روی RAM نگهداری میشه، مناسب نگهداری دادههای بلندمدت نیست. مثلاً اگه سرور ریاستارت بشه، تمام دادههای کش شده از بین میرن. به همین دلیل، اگه قراره دیتایی رو برای مدت طولانی نگهداری کنیم، باید حتماً اون رو داخل دیتابیس هم ذخیره کنیم و فقط به cache اکتفا نکنیم.
- Expiration policy: وقتی یه دیتا رو کش میکنیم، میتونیم برای اون یه مدت زمان مشخص (TTL) تعیین کنیم که مثلاً فقط یک ساعت توی cache بمونه. انتخاب این مدت خیلی مهمه. چون اگه خیلی کوتاه باشه، مدام مجبور میشیم بریم سراغ دیتابیس. اگه هم خیلی طولانی باشه، ممکنه دیتای ما قدیمی و غیرواقعی بشه. بنابراین باید برای هر نوع دیتا، یه expiration policy متناسب با رفتار اون دیتا تعیین کنیم.
- Consistency: باید حواسمون باشه که دیتای کش و دیتابیس با هم همخوانی داشته باشن. این موضوع زمانی مهم میشه که اطلاعات داخل دیتابیس تغییر کنن؛ چون ممکنه هنوز نسخهی قدیمی دیتا توی cache وجود داشته باشه. پس باید راهکاری داشته باشیم که وقتی دیتای اصلی آپدیت شد، دیتای کش شده هم invalidate یا بهروزرسانی بشه تا سیستم دچار مشکل ناسازگاری نشه.
- Mitigating failure: زمانی که فقط یک سرور کش داریم، سیستم ما ممکنه دچار Single Point of Failure بشه. یعنی اگه اون سرور کش به هر دلیلی از دسترس خارج بشه، ممکنه کل سیستم یا بخشی از اون دچار اختلال بشه، چون همه به اون سرور وابسته بودن. برای اینکه جلوی این مشکل رو بگیریم، میتونیم از چندین سرور کش استفاده کنیم. اینطوری اگه یکی از سرورها از کار بیفته، سرورهای دیگه میتونن بار رو به دوش بکشن و سیستم بدون مشکل به کارش ادامه بده.
- Eviction Policy: وقتی حافظه کش پر میشه و یه ریکوئست جدید بخواد آیتم تازهای رو به cache اضافه کنه، باید جا برای آیتم جدید باز بشه. این یعنی باید یه سری آیتم قدیمی از کش حذف بشن. یکی از پرکاربردترین سیاستها برای حذف آیتمها، Least Recently Used یا به اختصار LRU هست. توی این روش، آیتمی که قدیمیترین استفاده رو داشته از کش حذف میشه تا جا برای آیتم جدید باز بشه. این مدل کمک میکنه تا دیتاهایی که هنوز زیاد استفاده میشن، توی کش باقی بمونن و فقط دیتاهای بلااستفاده حذف بشن.
CDN
CDN به زبان ساده، شبکهای از سرورهای توزیعشده در نقاط جغرافیایی مختلفه که وظیفهشون تحویل محتوای استاتیک مثل عکس، ویدیو، CSS، JavaScript و فایلهای کششدهست. حالا بیایم ببینیم که CDN دقیقاً چطور کار میکنه.
وقتی یک کاربر وارد یک وبسایت میشه، نزدیکترین سرور CDN به اون کاربر، محتوای استاتیک رو براش تحویل میده. هرچی فاصلهی کاربر از سرور CDN بیشتر باشه، سرعت لود شدن سایت هم برای اون کاربر کمتر میشه.
برای مثال، اگه سرور CDN ما در San Francisco باشه، کاربرهایی که در Los Angeles هستن خیلی سریعتر محتوای استاتیک رو دریافت میکنن نسبت به کاربرهایی که در اروپا هستن.
به دیاگرام پایین دقت کنید تا ببینیم چطور یک CDN میتونه سرعت بارگذاری وبسایت رو برای کاربران در مناطق مختلف افزایش بده.
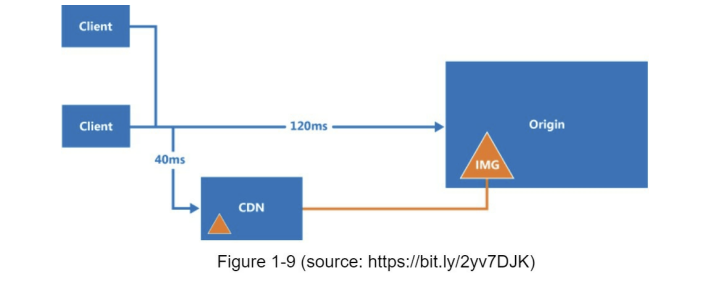
عکس پایین هم workflow یک CDN رو به ما نشون میده.
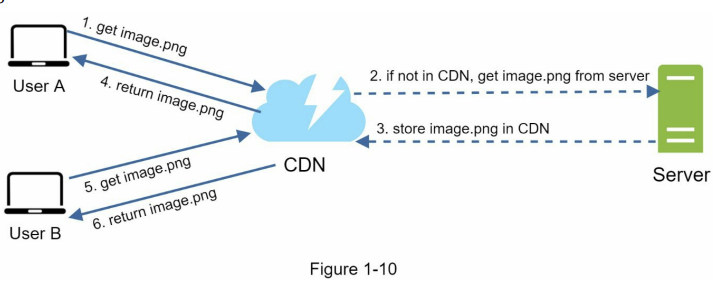
- User A با استفاده از URL عکس
image.pngرو دریافت میکنه. دامنهی این URLها معمولاً توسط CDN providerها مشخص میشن. دو نمونه از این URLها رو در پایین میبینید که به ترتیب برای Amazon CloudFront و Akamai هستن:- https://mysite.cloudfront.net/logo.jpg
- https://mysite.akamai.com/image-manager/img/logo.jpg
- اگر CDN عکس مورد نظر ما رو داخل cache نداشته باشه، یه request به سمت سرور منبع (origin server) ارسال میکنه تا اون فایل رو دریافت کنه. این سرور منبع میتونه مثلاً Amazon S3 باشه. بعد از دریافت فایل، اون رو داخل cache خودش ذخیره میکنه تا برای درخواستهای بعدی سریعتر تحویل بده.
- در این مرحله، Amazon S3 عکس ما رو همراه با یک HTTP header برمیگردونه که شامل کلیدی به نام TTL (Time To Live) هست. این TTL مشخص میکنه که این فایل قراره تا چه مدت داخل cache سرور CDN باقی بمونه و بعد از اون نیاز به بهروزرسانی داره.
- CDN عکس رو کش میکنه و به User A برمیگردونه. این عکس تا زمانی که به مقدار مشخصشده در TTL برسه، داخل cache CDN باقی میمونه و برای درخواستهای بعدی مستقیماً از همونجا سرو میشه.
- User B ریکوئست میزنه که همون عکس image.png رو بگیره
- عکس image.png از کش تا زمانی که expire نشده به کاربر برگشت داده میشه
ملاحضات استفاده از CDN
- هزینه: همونطور که CDNها رو از third-party providerها تهیه میکنیم، برای هر دادهای که روی این سرویسها قرار میگیره و استفاده میشه، از ما هزینهای دریافت میشه. اگه assetهایی داریم که خیلی کم استفاده میشن ولی همچنان توسط CDN کش شدن، بهتره اونها رو از CDN خارج کنیم یا کش شدنشون رو غیرفعال کنیم تا بتونیم در هزینهها صرفهجویی کنیم.
- تنظیم کردن یک expire policy مناسب:
- برای محتواهایی که حساس به زمان (time-sensitive) هستن، داشتن expire policy مناسب خیلی مهمه. زمان انقضای کش نباید خیلی طولانی باشه، چون ممکنه فایل بهروزرسانی شده باشه ولی نسخهی قدیمی همچنان در cache باقی بمونه. از طرفی، اگه expire time خیلی کوتاه باشه، باعث میشه که فایل مدام از سرور منبع (مثلاً Amazon S3) گرفته بشه، که هم هزینه رو بالا میبره و هم performance رو پایین میاره. بنابراین باید برای هر نوع فایل، زمان انقضای منطقی و متناسب با نوع و میزان تغییراتش در نظر گرفته بشه.
- نامعتبر کردن فایلها: برای اینکه بتونیم یک فایل رو قبل از اینکه زمان کش اون تموم بشه از CDN حذف یا بهروزرسانی کنیم، میتونیم از یکی از روشهای زیر استفاده کنیم:
- با استفاده از APIهای CDN vendorها میتونیم یک object رو بهصورت دستی نامعتبر (invalidate) کنیم. این یعنی حتی اگه TTL اون فایل هنوز تموم نشده باشه، CDN اون فایل رو از cache خودش حذف میکنه و برای درخواست بعدی، فایل جدید رو از سرور منبع (origin) دریافت میکنه. این روش مخصوصاً وقتی کاربرد داره که بخوایم سریعترین حالت ممکن یه فایل آپدیتشده رو به دست کاربر برسونیم.
- از Object versioning میتونیم برای سرو کردن نسخههای مختلف یک فایل استفاده کنیم. برای ورژنگذاری، میتونیم یک پارامتر مثل
versionبه URL فایل اضافه کنیم. مثلاً اگه بخوایم ورژن ۲ عکسimage.pngرو دریافت کنیم، URL به این صورت میشه:image.png?v=2با این روش، CDN فایل رو به عنوان یک object جدید شناسایی میکنه و نسخه قبلی رو نادیده میگیره، بدون اینکه نیاز باشه کش نسخه قبلی رو بهصورت دستی حذف کنیم. این تکنیک ساده، کنترل خوبی روی نسخهبندی فایلها بهمون میده.
بعد از اضافه کردن CDN دیاگرام ما به شکل زیر میشه:
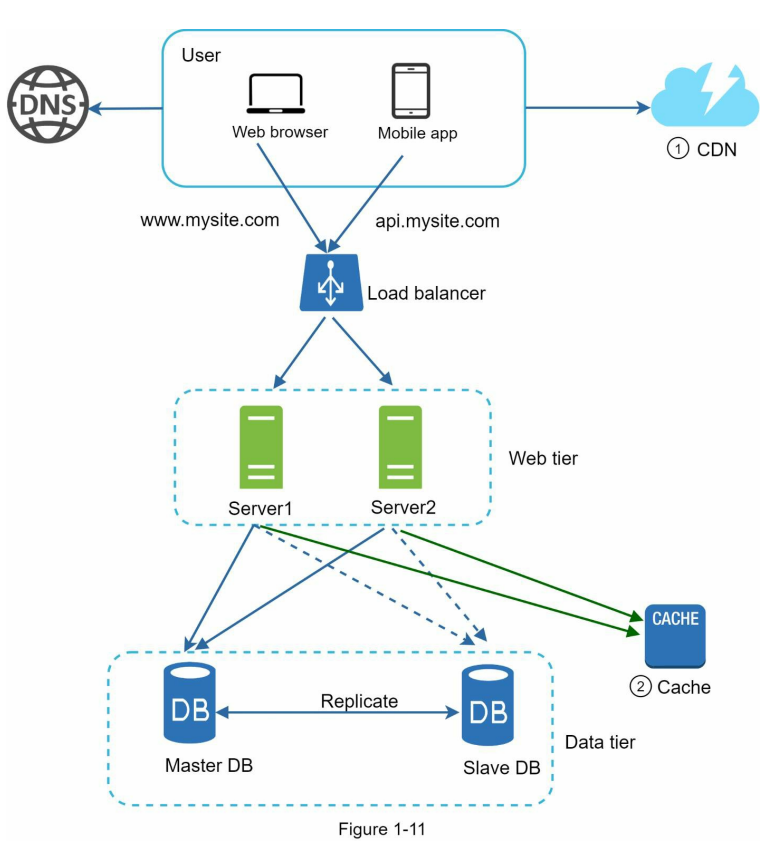
- فایلهایی مثل CSS، JS، عکسها و سایر محتوای استاتیک، دیگه مستقیماً از Web Server دریافت نمیشن و فقط از طریق CDN به کاربر تحویل داده میشن.
- Cache هم به سیستم اضافه شده تا درخواستهای پرتکرار از اونجا پاسخ داده بشن و در نتیجه فشار کمتری روی دیتابیس وارد بشه.
لایهی وب Stateless
حالا وقتشه که به مقیاسپذیری افقی (horizontal scaling) لایهی وب فکر کنیم. برای اینکه این کار رو انجام بدیم، باید state مثل اطلاعات سشن کاربر رو از لایهی وب جدا کنیم. یه روش خوب اینه که اطلاعات سشن رو داخل یه ذخیرهساز پایدار مثل دیتابیس رابطهای یا NoSQL نگه داریم. اینطوری هر وبسروری که داخل کلاستر هست، میتونه به این دیتا دسترسی داشته باشه. به این مدل، Stateless Web Tier گفته میشه.
معماری Stateful
سرورهای stateful و stateless چند تفاوت کلیدی با هم دارن. سرور stateful اطلاعات مربوط به کلاینت (state) رو از یک درخواست تا درخواست بعدی به خاطر میسپاره، در حالی که سرور stateless هیچ اطلاعاتی از وضعیت کلاینت نگه نمیداره و هر درخواست رو مستقل از درخواستهای قبلی پردازش میکنه. دیاگرام پایین یک مثال از معماری stateful را به ما نشون میده:
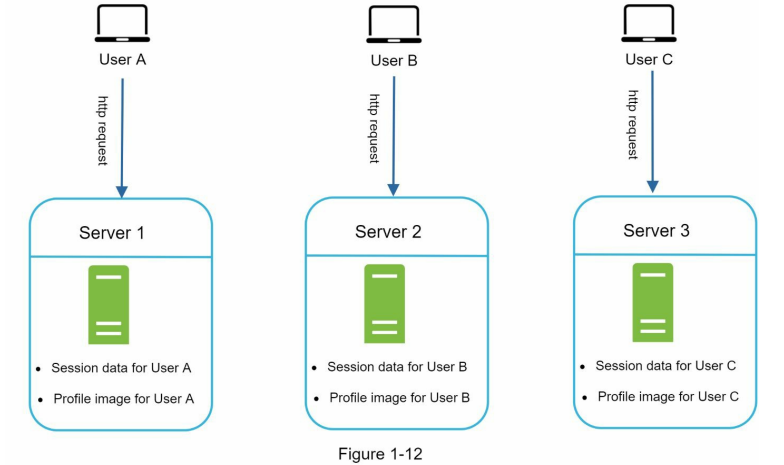
اطلاعات سشن و تصویر پروفایل کاربر A در Server 1 ذخیره شده. برای اینکه کاربر A احراز هویت بشه، باید درخواستهای HTTP حتماً به Server 1 فرستاده بشن. اگه این درخواست به سرور دیگهای مثل Server 2 بره، احراز هویت با خطا مواجه میشه چون Server 2 اطلاعات سشن کاربر A رو نداره.
به همین ترتیب، تمام درخواستهای کاربر B باید به Server 2 برن، و درخواستهای کاربر C هم باید به Server 3 ارسال بشن.
مشکل اینجاست که همهی درخواستهای یک کلاینت باید همیشه به همون سرور قبلی خودش برن.
این کار معمولاً با استفاده از قابلیت Sticky Session در load balancerها انجام میشه، اما این روش هزینهی اضافی و پیچیدگی ایجاد میکنه. با این مدل، اضافه یا حذف کردن سرور خیلی سختتر میشه و مدیریت خرابی سرورها هم چالشبرانگیزتر خواهد بود.
معماری Stateless
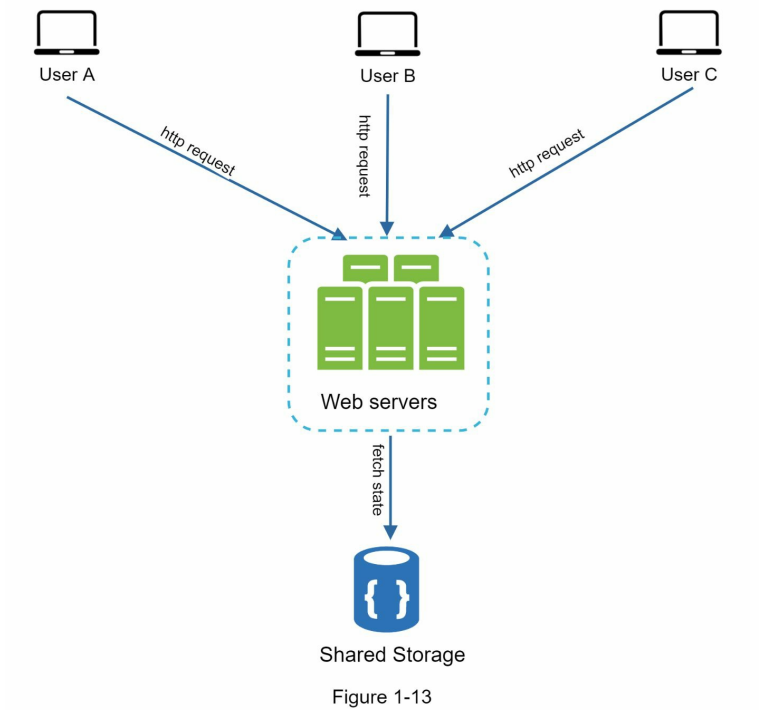
درخواستهای HTTP کاربران میتونن به هر کدوم از وبسرورها ارسال بشن، چون اطلاعات وضعیت (state) از یک مخزن دادهی مشترک دریافت میشن. توی این مدل، اطلاعات وضعیت داخل وبسرورها نگهداری نمیشن و همهی stateها داخل یک دیتاستور مرکزی ذخیره میشن. سیستمی که معماری stateless داشته باشه، معمولاً سادهتر و مقیاسپذیرتر هست.
دیاگرام پایین نسخه بروزرسانی شده دیزاین با استفاده از معماری stateless هستش.
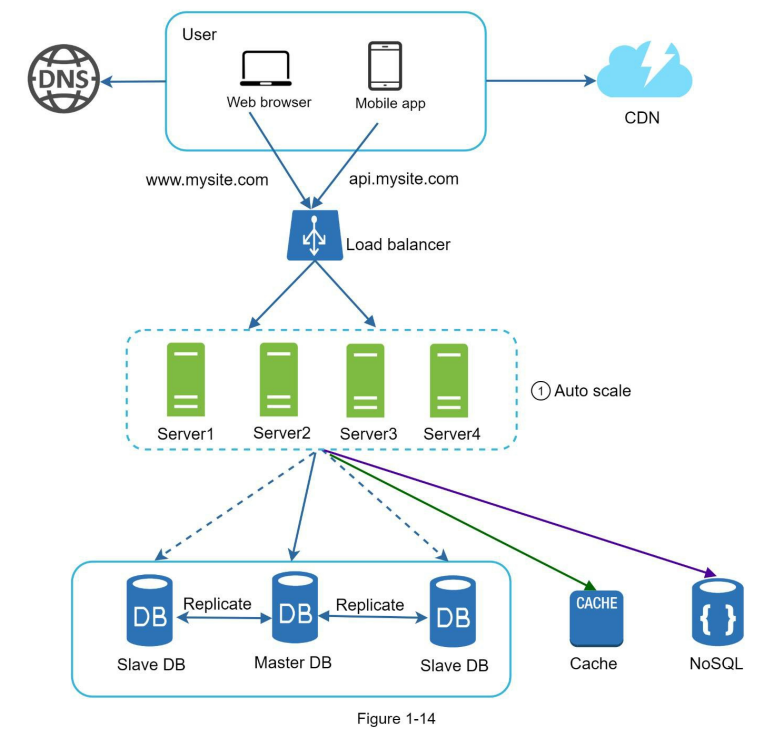
ما اطلاعات سشن رو از لایهی وب خارج میکنیم و داخل یک ذخیرهساز پایدار قرار میدیم. این ذخیرهساز مشترک میتونه یه دیتابیس رابطهای، Memcached، Redis یا NoSQL باشه. معمولاً NoSQL بهخاطر مقیاسپذیری راحتترش انتخاب میشه.
وقتی state از وبسرورها جدا بشه، میتونیم بهراحتی از Auto Scaling استفاده کنیم، یعنی بر اساس حجم ترافیک، بهصورت خودکار سرور اضافه یا حذف کنیم.
اگه وبسایت ما رشد کنه و کاربرهای زیادی از کشورهای مختلف داشته باشه، برای اینکه دسترسپذیری (availability) بیشتر و تجربهی کاربری بهتر در مناطق مختلف دنیا فراهم بشه، پشتیبانی از چند دیتا سنتر اهمیت زیادی پیدا میکنه.
Data centers
دیاگرام پایین یه نمونهای از راهاندازی سیستم با دو دیتا سنتر رو نشون میده.
توی شرایط عادی، کاربران با استفاده از geoDNS یا همون geo-routing به نزدیکترین دیتا سنتر هدایت میشن. بهطور مثال، ترافیک بهصورت تقسیمشده به شکل x٪ به دیتاسنتر US-East و (۱۰۰ – x)٪ به US-West فرستاده میشه.
geoDNS یک سرویس DNS هست که این قابلیت رو میده تا بر اساس موقعیت جغرافیایی کاربر، دامنه به IP مناسب همون ناحیه resolve بشه.
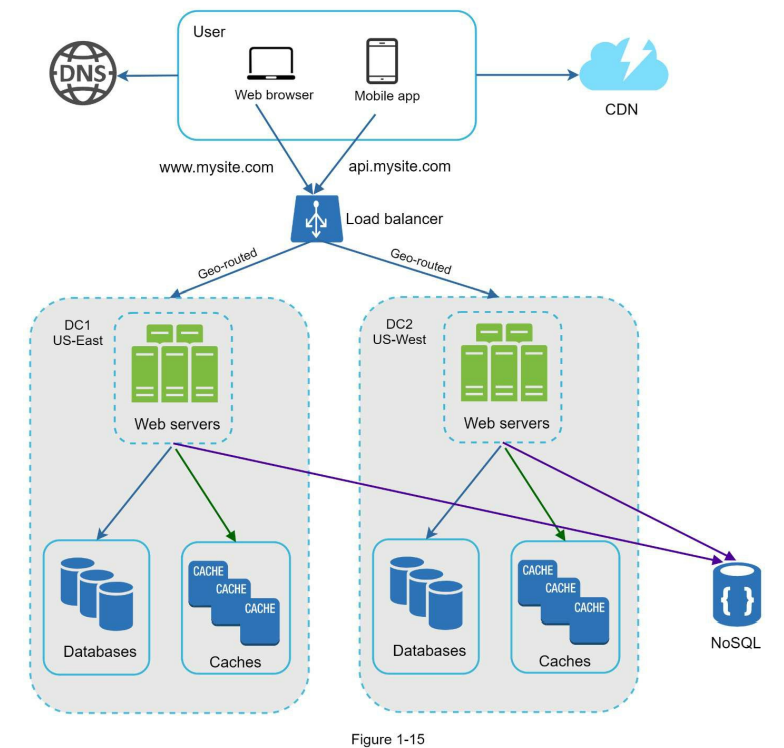
در صورتی که یکی از دیتا سنترها دچار اختلال جدی بشه، تمام ترافیک به دیتا سنتر سالم منتقل میشه.
توی شکل ۱-۱۶، دیتا سنتر ۲ (US-West) از دسترس خارج شده و به همین خاطر، ۱۰۰٪ ترافیک به سمت دیتا سنتر ۱ (US-East) هدایت میشه.
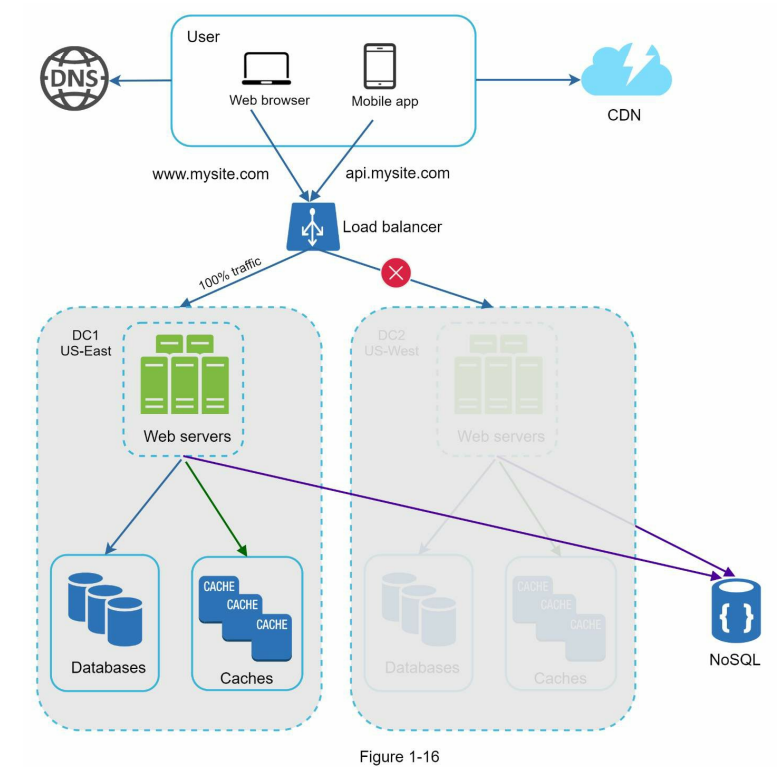
برای راهاندازی سیستم با چند دیتا سنتر، چند چالش فنی باید برطرف بشن:
- هدایت ترافیک: نیاز به ابزارهایی داریم که بتونن ترافیک رو به شکل درست به دیتا سنتر مناسب هدایت کنن. یکی از روشها استفاده از GeoDNS هست که بر اساس موقعیت جغرافیایی کاربر، نزدیکترین دیتا سنتر رو انتخاب میکنه.
- همگامسازی دادهها: کاربران از مناطق مختلف ممکنه به دیتابیسها یا کشهای محلی متفاوتی متصل باشن. در زمان failover ممکنه ترافیک به دیتا سنتری بره که دیتای لازم رو نداره. یه استراتژی رایج برای این مشکل، replicate کردن دادهها بین دیتا سنترهای مختلف هست. مطالعات قبلی نشون دادن که مثلاً Netflix از replication غیرهمزمان بین دیتا سنترها استفاده میکنه.
- تست و دیپلویمنت: در محیط چند دیتا سنتری، خیلی مهمه که وبسایت یا اپلیکیشن رو از لوکیشنهای مختلف تست کنیم. استفاده از ابزارهای دیپلویمنت خودکار باعث میشه که همه سرویسها توی تمام دیتا سنترها بهصورت سازگار و هماهنگ باقی بمونن.
برای اینکه سیستممون رو بیشتر مقیاسپذیر کنیم، باید کامپوننتهای مختلف سیستم رو از هم جدا کنیم تا بتونن بهصورت مستقل scale بشن.
یکی از استراتژیهای کلیدی که توی خیلی از سیستمهای توزیعشده واقعی استفاده میشه برای حل این مسئله، استفاده از message queue هست.
Message queue
Message queue یک کامپوننت پایدار و درون حافظه (memory) هست که از ارتباط غیرهمزمان (asynchronous communication) پشتیبانی میکنه.
Message queue نقش یه بافر رو بازی میکنه و درخواستهای غیرهمزمان رو توزیع میکنه. معماری پایهی اون خیلی سادهست: سرویسهایی که بهشون producer یا publisher گفته میشه، پیام تولید میکنن و اونها رو به message queue میفرستن. از اون طرف، سرویسها یا سرورهای دیگه که بهشون consumer یا subscriber میگن، به queue وصل میشن و عملیاتهایی که داخل پیام تعریف شده رو اجرا میکنن.

جدا کردن کامپوننتها از هم باعث میشه که message queue تبدیل به یکی از معماریهای محبوب برای ساخت اپلیکیشنهای مقیاسپذیر و قابلاعتماد بشه.
با استفاده از message queue، producer میتونه پیام خودش رو داخل صف قرار بده، حتی وقتی که consumer در اون لحظه در دسترس نباشه. از طرف دیگه، consumer هم میتونه پیامها رو از queue بخونه، حتی اگر producer در اون زمان در حال ارسال پیام جدید نباشه.
فرض کنید یه کاربردی داریم که توی اون اپلیکیشن، کاربران میتونن عکسهاشون رو شخصیسازی کنن؛ مثل بریدن (cropping)، تیز کردن (sharpening)، تار کردن (blurring) و…
این عملیاتها زمانبر هستن و بلافاصله انجام نمیشن.
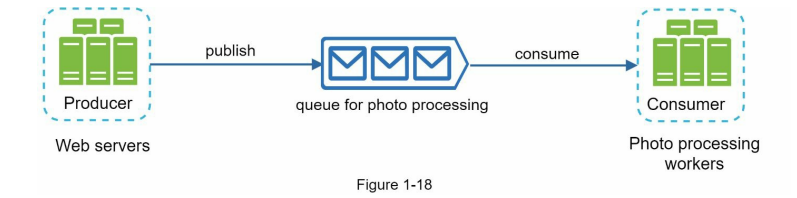
توی دیاگرام پایین، وبسرورها درخواستهای پردازش عکس رو به message queue میفرستن.
بعد، پردازشگرهای عکس (workers) این jobها رو از داخل صف برمیدارن و بهصورت غیرهمزمان شروع به انجام دادن عملیات شخصیسازی میکنن.
مزیت این معماری اینه که producer و consumer رو میتونیم بهصورت مستقل scale کنیم.
مثلاً وقتی اندازهی queue زیاد بشه، میتونیم workerهای بیشتری اضافه کنیم تا زمان پردازش کمتر بشه.
اما اگر صف بیشتر مواقع خالی باشه، میتونیم تعداد workerها رو کاهش بدیم تا منابع بیهوده مصرف نشن.
Logging – Metrics – Automation
وقتی با یه وبسایت کوچیک کار میکنیم که روی چندتا سرور اجرا میشه، داشتن ابزارهایی مثل لاگگیری، مانیتورینگ و اتوماسیون خوبه ولی الزام نیست. اما حالا که سایت رشد کرده و تبدیل به یه سرویس بزرگ برای کسبوکار شده، استفاده از این ابزارها کاملاً ضروریه.
Logging:
مانیتور کردن لاگهای خطا خیلی مهمه، چون کمک میکنه بتونیم خطاها و مشکلات سیستم رو سریعتر شناسایی کنیم.
میشه لاگها رو در سطح هر سرور بهصورت جداگانه بررسی کرد یا با استفاده از ابزارهایی، همهی لاگها رو تجمیع کرد توی یه سرویس مرکزی که بتونیم راحتتر دنبالشون بگردیم و مشاهدهشون کنیم.
Metrics:
جمعآوری انواع مختلفی از متریکها بهمون کمک میکنه تا هم دید بهتری نسبت به وضعیت سلامت سیستم داشته باشیم و هم بتونیم تحلیلهای بیزینسی دقیقتری انجام بدیم. برخی از متریکهای مفید شامل موارد زیر هستن:
- متریکهای سطح سرور: مثل مصرف CPU، رم، Disk I/O و…
- متریکهای تجمیعی: مثلاً عملکرد کلی لایه دیتابیس یا لایه کش
- متریکهای کلیدی بیزینسی: مثل تعداد کاربران فعال روزانه، نرخ بازگشت کاربران، درآمد و…
Automation:
وقتی سیستم بزرگ و پیچیده میشه، لازمه از ابزارهای اتوماسیون استفاده کنیم یا خودمون اونها رو بسازیم تا بهرهوری تیم بالا بره.
یکی از روشهای خوب، continuous integration (CI) هست که توی اون هر بار که کدی به مخزن اضافه میشه، بهصورت خودکار تست میشه تا بتونیم خیلی زود مشکلات رو شناسایی کنیم.
همچنین، اتوماسیون در فرآیند build، test و deploy باعث میشه بهرهوری تیم توسعه به شکل قابل توجهی افزایش پیدا کنه.
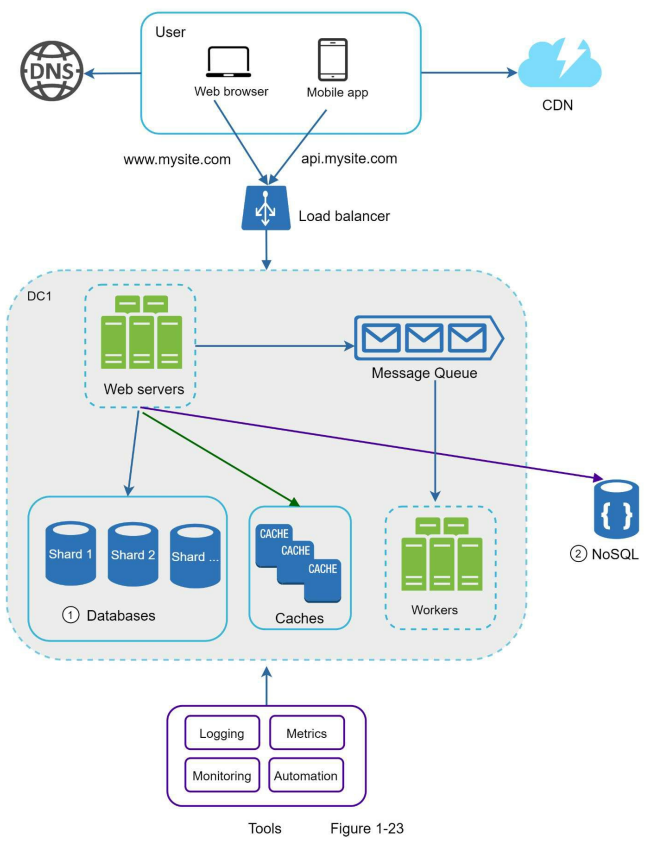
اضافه کردن message queue و ابزارهای مختلف
توی دیاگرام پایین، طراحی جدید سیستم رو میبینید. به خاطر محدودیت فضا، فقط یک دیتا سنتر در شکل نمایش داده شده.
- توی این طراحی، یک message queue اضافه شده که کمک میکنه سیستم loose-coupled تر بشه و در برابر خطاها مقاومتر عمل کنه.
- ابزارهای لاگگیری، مانیتورینگ، متریکها و اتوماسیون هم به سیستم اضافه شدن تا بشه راحتتر سیستم رو بررسی، مدیریت و توسعه داد.
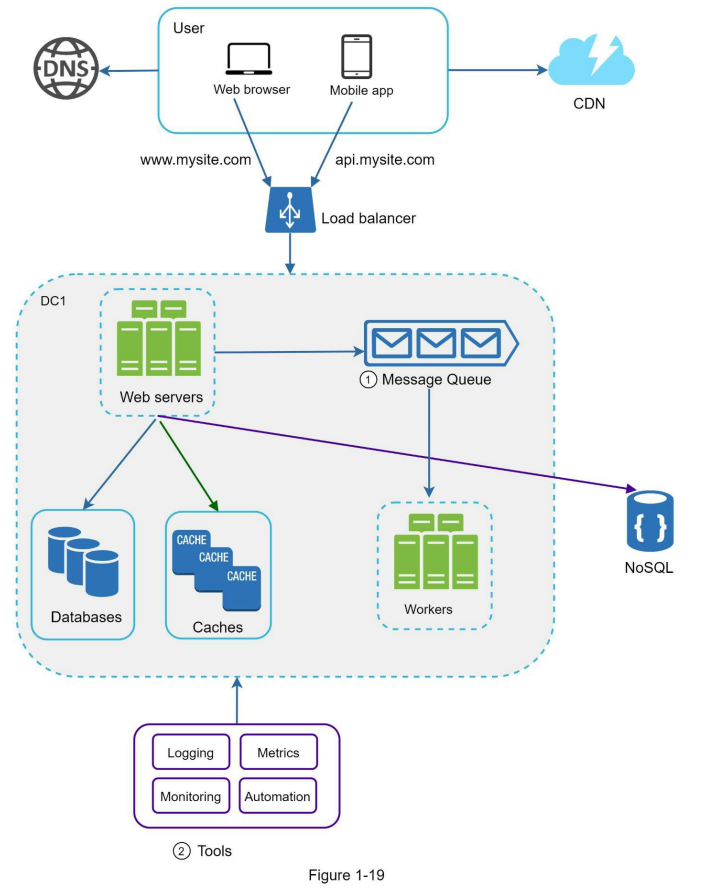
هر روز که حجم دادهها بیشتر میشه، فشار بیشتری روی دیتابیس وارد میشه. اینجاست که وقتشه لایهی دیتا (data tier) رو هم مقیاسپذیر کنیم.
Scale کردن دیتابیس
برای مقیاسپذیر کردن دیتابیس، بهطور کلی دو رویکرد اصلی وجود داره:
مقیاسپذیری عمودی (Vertical Scaling) و مقیاسپذیری افقی (Horizontal Scaling).
مقیاسپذیری عمودی (Vertical Scaling)
مقیاسپذیری عمودی که بهش scale-up هم گفته میشه، یعنی اینکه با اضافه کردن منابع بیشتر مثل CPU، RAM، دیسک و… به یک ماشین موجود، قدرت اون سرور رو افزایش بدیم.
برخی از دیتابیس سرورها قدرت خیلی بالایی دارن. مثلاً طبق اطلاعات Amazon RDS، میتونید یه سرور دیتابیس با ۲۴ ترابایت RAM داشته باشید. این نوع سرورها میتونن مقدار زیادی از دادهها رو نگهداری و پردازش کنن.
برای مثال، وبسایت StackOverflow در سال ۲۰۱۳ با بیش از ۱۰ میلیون کاربر فعال ماهانه، تنها از یک دیتابیس master استفاده میکرد.
با این حال، vertical scaling معایب جدیای داره:
- شما میتونید منابع بیشتری مثل CPU یا RAM به سرور اضافه کنید، اما در نهایت با محدودیتهای سختافزاری مواجه میشید. اگه تعداد کاربران زیاد باشه، یه سرور کافی نیست.
- خطر نقطه شکست واحد (single point of failure) بیشتر میشه، چون همهچیز به یه سرور وابستهست.
- هزینهی کلی vertical scaling بالاست. چون سرورهای قویتر، خیلی گرانتر هستن.
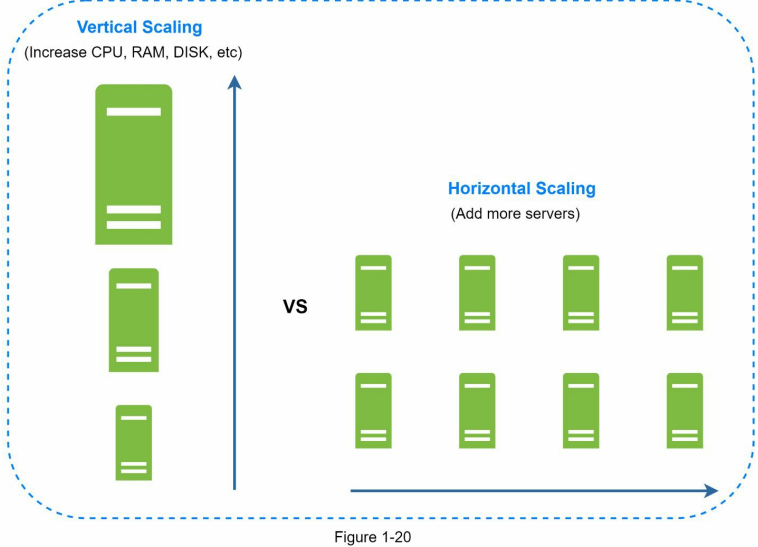
مقیاسپذیری افقی (Horizontal Scaling)
مقیاسپذیری افقی که بهش sharding هم گفته میشه، یعنی اینکه بهجای ارتقا دادن یه سرور، تعداد سرورها رو بیشتر کنیم.
توی دیاگرام پایین، مقایسهای بین vertical scaling و horizontal scaling انجام شده. Horizontal scaling این امکان رو میده که بار سیستم رو بین چند سرور تقسیم کنیم، در حالی که vertical scaling فقط به قویتر کردن یه سرور متکیه.
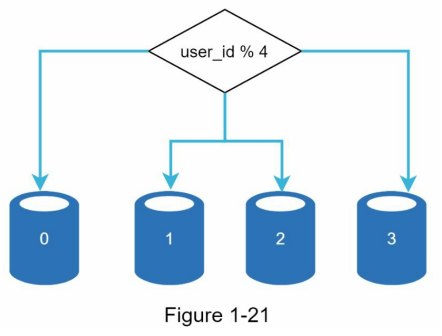
Sharding دیتابیسهای بزرگ رو به بخشهای کوچکتر و قابل مدیریتتری به اسم shard تقسیم میکنه.
هر shard دارای ساختار (schema) یکسان با بقیهی shardهاست، اما دادههایی که در هر shard وجود داره منحصر به همون shard هست و با shardهای دیگه فرق میکنه.
توی دیاگرام پایین، یک نمونه از دیتابیسهای sharded رو میبینید. توی این مثال، دادههای کاربران بر اساس user ID بین سرورهای مختلف تقسیم شدن.
هر بار که نیاز داریم به دادهای دسترسی پیدا کنیم، از یه تابع هش (hash function) برای پیدا کردن shard مربوطه استفاده میکنیم.
در این مثال، از تابع user_id % 4 استفاده شده.
اگه نتیجه برابر با 0 باشه، دیتا داخل shard 0 ذخیره یا از اون خونده میشه.
اگه نتیجه برابر با 1 باشه، shard 1 استفاده میشه.
همین منطق برای shardهای دیگه هم صدق میکنه.
دیاگرام پایین جدول users رو توی یک دیتابیس shard شده نشون میده
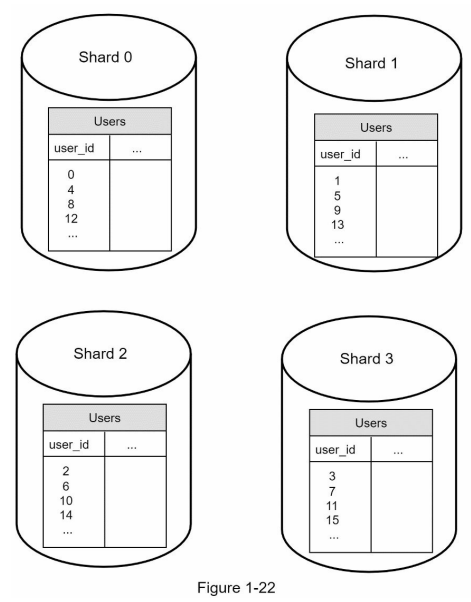
مهمترین نکتهای که هنگام پیادهسازی یک استراتژی sharding باید بهش توجه کنیم، انتخاب کلید sharding یا همون sharding key هست.
Sharding key (که بهش partition key هم گفته میشه) از یک یا چند ستون تشکیل میشه که تعیین میکنن دادهها چطور بین shardها تقسیم بشن.
همونطور که توی دیاگرام بالا دیدیم، ستون user_id به عنوان sharding key استفاده شده. وجود یه sharding key مناسب باعث میشه که کوئریها مستقیماً به shard درست هدایت بشن و عملیات read/write بهشکل بهینه انجام بشه.
یکی از مهمترین معیارها در انتخاب sharding key اینه که بتونه دادهها رو بهصورت یکنواخت (evenly) بین shardها تقسیم کنه تا از عدم تعادل و تمرکز بار روی یک shard خاص جلوگیری بشه.
Sharding تکنیک بسیار خوبی برای مقیاسپذیری دیتابیس هست، اما به هیچوجه راهحل کاملی نیست. این روش پیچیدگیها و چالشهای جدیدی رو به سیستم اضافه میکنه:
Resharding دادهها:
زمانی به resharding نیاز داریم که:
۱) یه shard بهخاطر رشد سریع دیگه نتونه دادهی بیشتری رو نگهداری کنه
۲) توزیع دادهها بهصورت یکنواخت انجام نشده و بعضی shardها زودتر از بقیه پر میشن
در این حالتها باید تابع sharding تغییر کنه و دادهها به shardهای جدید منتقل بشن. برای حل این مسئله، consistent hashing (که در فصل پنجم بررسی میشه) یکی از راهحلهای رایجه.
Celebrity Problem:
به این مشکل hotspot key هم گفته میشه. وقتی یه shard خاص بیش از حد درگیر بشه، میتونه باعث بار اضافی و کندی سرور بشه.
مثلاً اگه اطلاعات مربوط به افراد پرطرفداری مثل Katy Perry، Justin Bieber یا Lady Gaga همه داخل یک shard قرار بگیرن، اون shard توی اپلیکیشنهای اجتماعی با حجم زیادی از عملیات خواندن (read) روبهرو میشه.
برای حل این موضوع، میتونیم یه shard مجزا برای هر سلبریتی اختصاص بدیم و حتی در صورت نیاز اون shard رو هم به بخشهای کوچیکتر تقسیم کنیم.
Join و denormalization:
بعد از sharding دیتابیس بین چند سرور، انجام عملیات join بین shardها بسیار سخت میشه.
یه راهحل رایج برای این مشکل اینه که ساختار دیتابیس رو denormalize کنیم تا کوئریها روی یه جدول اجرا بشن و نیازی به join بین چند shard نباشه.
توی دیاگرام پایین، دیتابیسها برای مدیریت ترافیک بالای دادهها shard شدن و در کنارش، بخشی از قابلیتهایی که حالت رابطهای ندارن، به یه دیتابیس NoSQL منتقل شدن.
میلیونها کاربر و فراتر از آن
مقیاسپذیر کردن یک سیستم، یه فرآیند تکراریه. با تکرار کردن چیزهایی که توی این فصل یاد گرفتیم، میتونیم سیستم رو تا حد زیادی توسعه بدیم. اما برای رسیدن به مقیاسی فراتر از میلیونها کاربر، باید بهینهسازیهای بیشتری انجام بدیم و حتی استراتژیهای جدیدتری پیاده کنیم.
برای مثال، ممکنه لازم باشه سیستممون رو به سرویسهای کوچکتر و مستقلتر تقسیم کنیم تا بهتر بتونه ترافیک بالا رو هندل کنه. تکنیکهایی که توی این فصل بررسی کردیم، پایهی خوبی برای مقابله با چالشهای جدید هستن.
برای جمعبندی، این خلاصهای از کارهایی هست که برای مقیاسپذیر کردن سیستم و پشتیبانی از میلیونها کاربر انجام دادیم:
- لایهی وب رو stateless نگه داشتیم
- در تمام لایهها، redundancy ایجاد کردیم
- تا جای ممکن دادهها رو cache کردیم
- از چند دیتا سنتر پشتیبانی کردیم
- فایلهای استاتیک رو روی CDN قرار دادیم
- لایهی دیتا رو با sharding مقیاسپذیر کردیم
- لایهها رو به سرویسهای مجزا تقسیم کردیم
- سیستم رو مانیتور کردیم و از ابزارهای اتوماسیون استفاده کردیم
مقاله ای عالی با معادل سازی دقیق، بیان شیوا و مختصر و فرمت بندی حرفه ای. ممنون از نویسنده محترم
ممنون از محبت شما، خوشحالم براتون مفید بوده
زنده باد. خیلی عالی بود
قربان شما، مشتی هستی
خیلی عالی بود
ممنونم
ممنون از وقتی که گذاشتید